Rails offer us a mechanism through the db/seeds.rb file, which allows us to write Ruby code and use our application’s models to populate the database. Want to know the best practices? Read this.
Best practices using Rails Seeds
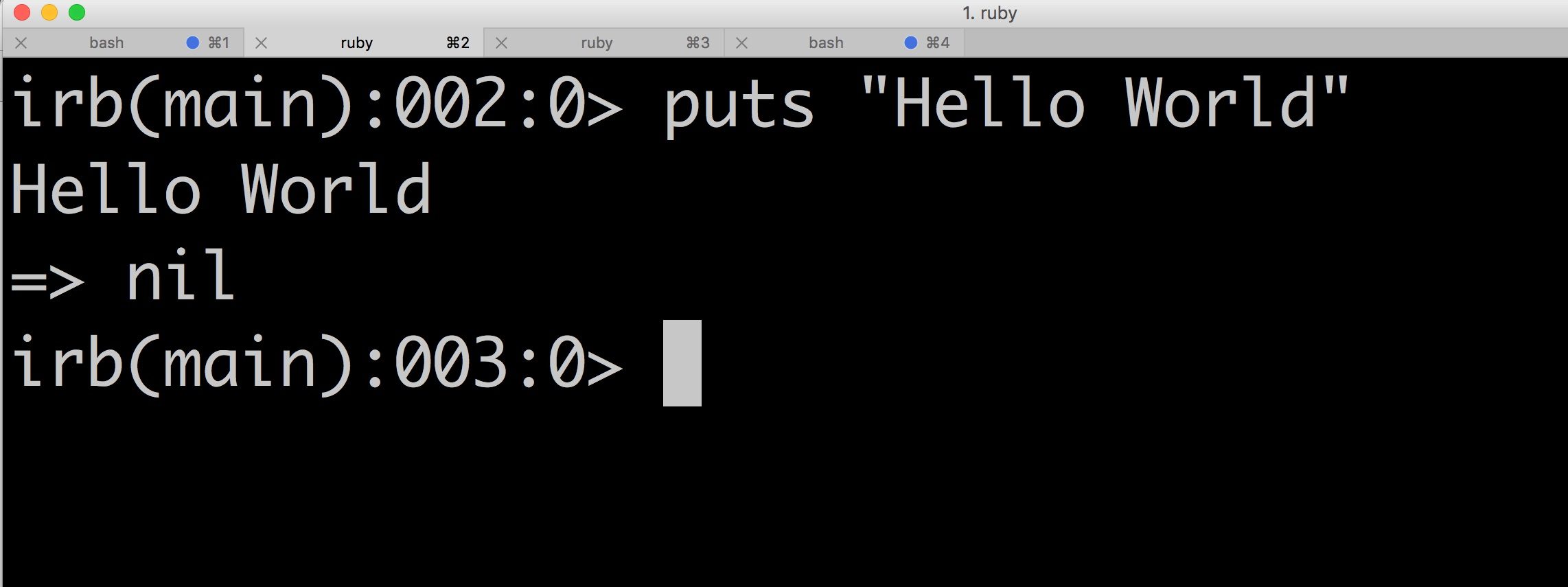
Rails seeds are useful since they help us populate the test and development DBs with data. This means that we can simply run rails db:seed for rails 5 —and beyond, or rake db:seed for rails 4 —and prior— and have the app up and running with enough information to be productive right away.
By the way, Rails documentation has a pretty good definition for the seeds:
To add initial data after a database is created, Rails has a built-in
'seeds' feature that makes the process quick and easy. This is
especially useful when reloading the database frequently in development
and test environments. It is easy to get started with this feature: just
fill up db/seeds.rb with some Ruby code, and run rails db:seed
Best practices
Break them into smaller files
By default, rails encourage you to put the logic of the initial data creation inside the db/seed.rb file, but over time that file could become huge and complex. One solution to prevent this from happening is to create a file per model or group of data and then load them into the seed.rb. For example, let’s suppose we have a web page to manage doctors’ appointments. In that case, we would have the models: User, Roles and Appointment.
Then, we create a new seeds folder inside the rails DB folder to store the following 3 seed files with the following names: app/db/seeds/001_roles.rb, app/db/seeds/002_users.rb and app/db/seeds/003_appointments.rb
We create them with that naming convention to be able to control the loading order of the seeds; this is helpful when we have models that depend on the data created by other models like Appointment that needs a doctor and a patient to exist or the users that need roles to be identified within the app. Once we create our seeds files, we can load them into the seed.rb file with the following code:
Dir[Rails.root.join('db/seeds/*.rb')].sort.each do |file|
puts "Processing #{file.split('/').last}"
require file
end
Unique records
For some devs, it is common to run the seeds command (rails db:migrate or rake db:migrate) because sometimes they forget if they have already run them and, other times because they have edited a seed file (which should not be a problem nor create data duplication) that is easily fixed by adding the seeds data using the rails methods find_or_create_by. Following the appointments app example we would do something like this:
app/db/seeds/001_roles.rb
Role.find_or_create_by(name: ‘Patient’) do |patient|
Patient.availability = ‘8-5’
end
Role.find_or_create_by(name: ‘Doctor’)
app/db/seeds/002_users.rb
patient_role = Role.find_by_name(‘Patient’)
doctor_role = Role.find_by_name(‘Doctor’)
User.find_or_create_by(first_name: ‘John’, last_name: ‘Doe’, role: patient_role)
User.find_or_create_by(first_name: ‘Janne’, last_name: ‘Doe’, role: doctor_role)
By saving the records like that, we can avoid duplicating the data that we already have in the DB (if any). You could try something a little bit different if you like/need to do so, nevertheless, I did it this way myself:
patient_role = Role.find_by_name(‘Patient’)
User.where(first_name: ‘John’, last_name: ‘Doe’).first_or_create do |user|
user.role = patient_role
end
Hope this works for you. Thanks for reading!